

看到一些在黑盒优化的问题上(Nerual Structure Search或电路优化等)有人在强化学习这方面做了些成果,想知道相比贝叶斯优化、粒子群算法、遗传算法这样的启发式搜索算法,强化学习有什么好处?这两类算法又分别有什么优点和不足?
1,和粒子群,差分进化算法比,强化学习的优点在于充分利用了历史样本。任何优化算法都需要寻找一个下降或者以一定概率下降的方向。梯度优化算法选择负梯度,粒子群,差分进化则通过与最优解随机杂交得到高概率下降方向。以上算法,都只利用了当前最优样本来更新,而强化学习基于评价函数得到下降方向,由于评价函数是基于所有已有样本的,因此信息利用更充分。
2,在马尔科夫序列的优化上,强化学习比贝叶斯优化更强。贝叶斯优化和强化学习一样,也基于历史样本建模得到代理模型/评价函数,从而也可以充分利用已知样本。但是在马尔科夫序列的优化中,强化学习在每一个序列节点评价函数的输入是当前状态,而贝叶斯算法需要将整个已知序列作为输入,维度高,建模更难。可见,强化学习充分利用了问题本身的结构,减少了建立评价函数所需样本,效率更高。
综上,强化学习的优点在于充分利用优化问题的先验结构(马尔科夫性),以及已有的样本。所以,如果你想针对特定过程开发一种比强化学习更强的优化算法,那也一样需要充分利用问题的特殊结构,充分利用已知样本。懂了没?
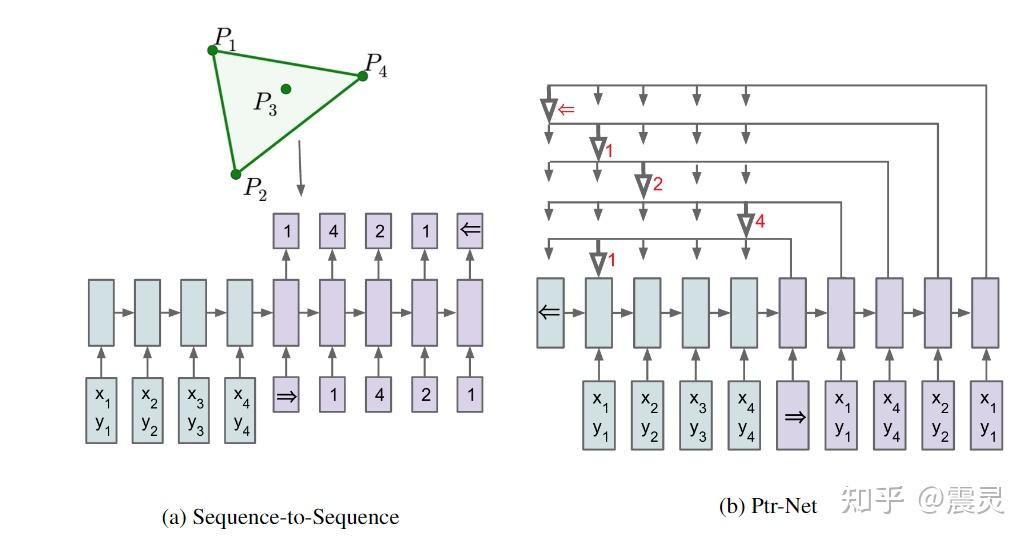
最大的好处就是神经网络的可塑性非常强,并且号称具有迁移学习能力。举一个最简单的例子,对于传统优化问题来说,无论是贝叶斯优化还是启发式算法,对于每求解一组新问题,都需要针对每个实例(例如一个TSP路径规划实例)运行一次完整的优化算法。但是实际上这些问题的最优解可能有某种强关联,对于这种情况,基于神经网络的强化学习算法一旦解决了其中某一个问题,就有可能快速求解其他问题。一个直观的理解就是Pointer Network,通过监督学习/强化学习,神经网络可以根据已经求解的TSP方案确定一个新的TSP规划问题的方案。
但是,上述情况只是理想情况,在真实的基于强化学习的优化场景中,强化学习的训练过程其实相当复杂,目前的主流算法A3C和PPO目前来看并不能高效利用搜索过程中的知识。目前来看,RL算法在调参之后可以达到近似专业求解器的效果。但是短期来看,鉴于专业求解器的可解释性和鲁棒性,基于强化学习的优化算法依然有较大的提升空间。下图是港中深的查宏远老师AAAI 2021年的RL-Based TSP Solver的最新成果,可以看到RL方法尽管已经有非常大的进展,但是相比启发式方法依然有一定程度的差距。
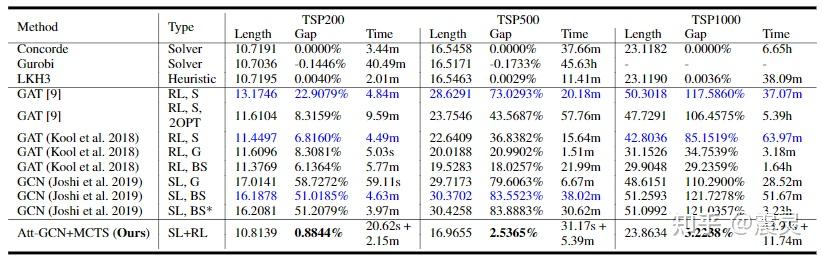
上面有提到,神经网络擅长学习而不擅长搜索,而传统搜索算法,例如演化算法和启发式搜索算法擅长搜索而不擅长学习。考虑到这种困境,其实一个很好的解决方案是让演化算法去搜,然后让神经网络去看着演化算法的结果学习。目前来说,优化算法和强化学习的结合已经逐渐引起了大家的注意。在目前的基于强化学习的TSP求解算法中,已经有不少的算法尝试先基于近似最优解(Oracle)进行imitation learning/supervised learning,随后再使用强化学习算法进行学习。上图所示的SL+RL就代表了这种思想,可以看到相比传统的单纯基于RL或SL的Deep Learning Solver,这种混合了启发式算法知识和强化学习策略的求解器可以取到更好的性能。可以预见,在未来,这样的模式将会被广泛推广到Bin Packing、Job Shop Scheduling等各个组合优化领域,相比与熟优熟劣的争执,这种对不同算法的结合策略显然是更有价值的。
两年过去了,对问题有了一些新的理解,自问自答一下吧,期望说的不到的地方有大神可以补充,学习一下~
其实正如高赞回答所说,神经网络擅长学习而不擅长搜索,而传统搜索算法擅长搜索而不擅长学习。目前根据我的实验结果,传统的优化算法诸如BO、PSO、EA要比DRL效果好的多,稳定性也高的多,无论从搜索的效果还是收敛速度上来说都是这样。比如BO只需要搜索300次,就可以到最优点;基于种群进化的算法:种群25,迭代30次,也可以到最优点。但对于DRL,迭代了1e4次,也勉强才到次优点。DRL的收敛曲线差不多是图1这样(PPO找Ackely函数的最优点([1]*n)),一个明显的趋势是,DRL后面的表现越来越稳定(当然对于其他算法来说也应该是这样)。

究其原因,个人认为大概有几点:1)DRL的探索方式很低效,只是在action上加噪声;而BO是根据采集函数进行的,基于种群的进化算法相当于变向利用了梯度信息; 2)DRL的死亡三角问题,让数据利用率本身就很低。3)个人认为DRL本身不适合做一些精细化的操作,因为这要求调整超参数让算法表现的很激进,带来的后果就是收敛速度慢,甚至无法收敛。
所以相比已有的搜索算法来说,DRL很难或者不适合部属在样本比较贵的场合下。就我看到的应用场景,都是用廉价数据去近似昂贵数据。比如Google的芯片自动化布局布线中,是用走线长度近似PPA。还有在早期的NAS中,评估结果的时候也仅对生成的神经网络训练1个epoch。
但从积极的角度来说,传统优化算法的执行是一次性的,当有一个新的任务时,需要从头执行一次,很难做到迁移学习的(也许有一些tricky的方法,比如MTBO、或者复用历史记录,但似乎不够优雅)。而神经网络的迁移学习更加灵活,利用简单的pre-train与fine-tuning,在新的相关联任务上很容易就会有效果。即便从大多数DRL应用场景来看,通常是训练一个网络在实际场景中去做应用与调度,而不是训练结束后就扔掉了。
此外,神经网络的特征提取能力,也可以帮助解决一些实际中的困难。具体来说,已有的优化算法都是直接在欧式空间上进行优化的,但这在一些应用场景中不是很明智的选择,因为有些应用场景在欧式空间里的响应很不平坦,或者有些维度有些冗余或者相关性,而传统算法都不能有效的处理这些场景。
优化问题一般分为多目标/单目标的离散/连续问题。
目前处理连续的多目标和单目标问题的主流方法依然是包括演化算法的启发式和元启发式算法,因为机器学习做这类问题算是大材小用。若是问题昂贵,强化学习可以派上一定的用场,作为一种新的建立代理模型的学习算法。
对于单目标、多目标的离散优化问题,尤其是组合优化问题,目前已经有大量的从业者研究这些领域。强化学习方法相比启发式学习在同一测试问题上有两个明显的优势,速度快,可并行性高。同样,机器学习方法由于是基本只需要reward function 来监督,处理没有人类经验,我们不熟悉的优化问题上,可能会比那些问题上的元启发式算法要好。
这个领域的方法分为两种,都比较自然,一类是把优化看作解空间映射问题学习映射,另一类是学习特定算子的元启发式方法。这两类算法有着两个对应的巨大问题,前者的强化学习资格迹太长,等于点的个数,会导致收敛慢,陷入局部最优。后者从初始解到优化结束过程比较长,直观的说就是前边的优化过程都是没用的,数据利用率极低。
未来强化学习要是希望能够在单纯结果上超过启发式可以利用启发式的核心过程。已经有的学者做了这个方向,比如学习LKH中的几个步骤。或者可以等待下一次RL的技术革新,可能是结合了表示学习或者对比学习之类的RL算法。
关于强化学习和传统优化算法(包括:数学优化,启发式,元启发式)的探讨越来越多了,很多同学可能是一上来就集中在一个方向和方法上,并没有在全局的视角去审视这几类方法的不同。我这里就做一个总结,欢迎各位来讨论:
没学过强化学习的同学,应该是知道动态规划的吧。强化学习实际上起源于动态规划,而动态规划和强化学习解决的是一个动态优化问题或者说是序列优化问题。学过强化学习的同学都知道一个叫做马尔科夫决策过程的概念(Markov Decision Process)。进一步地,由于强化学习继承了动态规划和马尔科夫决策过程的基本框架,使得强化学习依然具备一些传统动态规划和马尔科夫决策过程的理论保障。强化学习善于解决动态优化问题并不完全是一种感性的认识,在着后边还具备着严谨的理论支撑。
反观贝叶斯优化、粒子群算法、遗传算法这样的启发式搜索算法,还有传统的数学优化方法主要是针对静态的优化问题而设计的。虽然这些方法也不是不能用来解动态(序列)优化问题,但相比强化学习来说 它们这些方法 1是缺乏理论保障;2是实际效果确实也差。
任何组合优化问题都可以等价转化为一个序列优化问题,关于这一条的推导证明 我这里就不重复了,想看细节的同学可以看看 @覃含章 的回答。
现在研究强化学习+组合优化的paper不少了(几十篇+),但方法似乎就这么几种,对此您怎么看?总之,组合优化问题也可以被看成是一个序列(动态)优化问题。那么再结合上一条,那就很明显可以得出:强化学习也可以被用来求解组合优化问题。
进一步地,用强化学习来解组合优化问题是非常有优势的,强化学习虽然不能把组合优化问题从NP-hard变成P的,但是至少可以把复杂度为阶乘级的算法变成指数级的,详细的推导证明可以参考我之前的回答:
现在研究强化学习+组合优化的paper不少了(几十篇+),但方法似乎就这么几种,对此您怎么看?强化学习的输出严格来说不是一个最优的Action,而是一个最优的Policy。Policy的本质上是一个最优的规则,数学上来说是一个映射。如下所示:
上式中 就是一个Policy,它是由一个从状态空间
到动作空间
的映射。也就是说任意给我一个状态
,我只要把这个
带入到Policy中去都可以得到最优的Action。
反观贝叶斯优化、粒子群算法、遗传算法这样的启发式搜索算法,还有传统的数学优化方法 输出的是一个最优的Action(Decision variable)。
输出Policy到底比输出最优Action好在哪里呢?最主要的好处是 Policy 可以有效的克服系统中的各种扰动。在系统发生扰动的时候,强化学习往往不需要从头开始进行重新的优化,而贝叶斯优化、粒子群算法、遗传算法这样的启发式搜索算法,还有传统的数学优化方法 就必须完全从头开始进行优化。在传统优化问题领域我们经常会听说 reschedule/re optimize 等问题,这是因为一旦扰动发生我们只能去完全重新的去做决策。而强化学习因为输出的是一个Policy 自然 reschedule/re optimize 的事情就不复存在了。
这个特性是基于Learning的方法所带来的优势。在机器学习领域有一个子方向叫做 Transfer Learning (迁移学习)。简单来说就是一个神经网络本来我是让这个神经网络学习识别猫的图片的,但是如果给我一个能够识别狗的神经网络是能帮助我这个识别猫的图片的神经网络更快更好的学习的。这就涉及到不同学习任务之间的迁移,不同的学习任务可能是能互相关联和互相帮助。
那么把这个Transfer Learning (迁移学习)的概念平行得挪到优化问题里去看,我们马上就会思考这样一个问题。如果我能很好的求解A类优化问题,那是不是可以帮助我可以更好更快的去求解B类优化问题。自然这里面隐含了一个条件就是A和B这两类优化问题是有某种程度的相似性的。
这个问题就是我这里提到的迁移优化(Transfer Optimization)。实际上在强化学习中,我们很可能会在强化学习中使用神经网络这类的机器学习模型,自然也就具备了实现相似优化问题之间可以迁移的可能性。具体关于这一点就不具体再展开讨论了,感兴趣的童鞋欢迎评论留言讨论。

